





























The Distributed Connector Pattern: Why Where You Query Matters More Than How Fast
Part 1 of a series on scaling data-intensive applications
Coming in 2026: The distributed connector architecture described in this series is planned for an upcoming XMPro release. This series shares our engineering findings and the architectural approach we’re taking.
In distributed systems, the question of where computation happens often matters more than how fast it runs. A query that executes quickly can still bottleneck your application if it runs in the wrong process.
We recently had the opportunity to measure this directly when comparing two architectural approaches for data connectors in XMPro Application Designer. The results were instructive—and the pattern that emerged applies well beyond our specific use case.
The In-Process Connector Model
Most application frameworks start with a straightforward approach to data access: the application process itself executes queries and retrieves results. This model is simple to reason about, easy to debug, and works well at moderate scale.
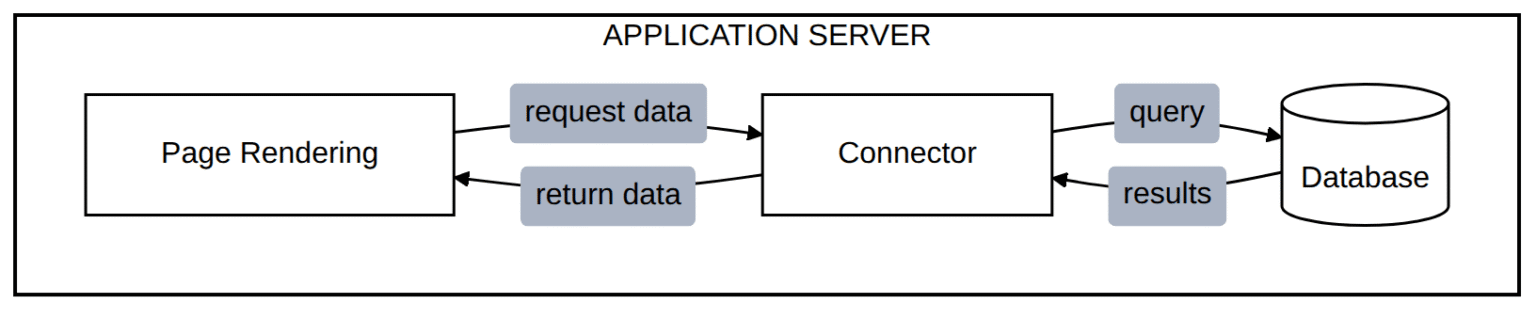
All work competes for the same CPU and memory
The architecture has an implicit assumption: data retrieval is fast relative to other work the application performs. When queries return quickly and payloads are small, this assumption holds. The connector work is a rounding error in the overall request lifecycle.
But assumptions have boundaries.
When the Model Breaks Down
As applications mature, several pressures challenge the in-process model:
- Concurrent users increase — More users mean more simultaneous queries competing for the same process resources
- Data volumes grow — Payloads expand from kilobytes to megabytes
- Pages become data-rich — A single page might require three, four, or five separate data sources
- Query complexity increases — Simple lookups evolve into aggregations and joins
None of these changes require the application to be “broken.” They simply shift the workload profile beyond what the original architecture optimised for.
The Hidden Cost of Connector Loading
In XMPro’s in-process model, there’s overhead that compounds these pressures. Each time a page requests data from a connector:
- The connector assembly is fetched from the database — including all binary files, loaded into memory
- The connector is instantiated — creating a new instance per request
This happens on every data request, not just the first one. While the system caches “live” connectors in memory, standard connectors have no server-level caching. A page with three data grids triggers this cycle three times—database fetch, assembly instantiation—before any actual data query executes.
The pattern we observed: at some concurrency threshold, the application server spends more time loading and instantiating connectors than rendering pages. The connector overhead—originally a small fraction of the request—becomes the dominant consumer of CPU and memory. Page rendering queues behind connector instantiation, which queues behind database retrieval of connector binaries.
The Distributed Connector Pattern
The architectural response is to move connector execution out of the application process entirely. Rather than the application server querying databases directly, it delegates to a separate service layer purpose-built for data operations.
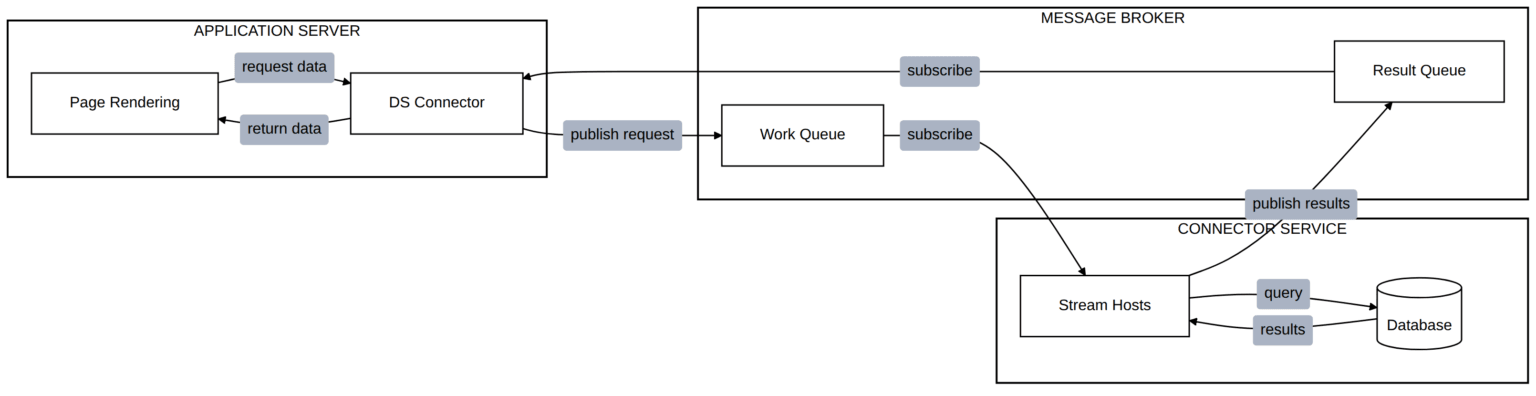
Query execution offloaded to dedicated stream host collection
The key insight: the application server no longer loads connector assemblies or executes queries. The DS Connector is a lightweight, built-in connector—no binary loading, no assembly instantiation. It simply publishes a request to a message broker, and a stream host collection—where the connector assemblies are already loaded and running—performs the actual database work. Results flow back through the broker.
This eliminates the per-request overhead entirely. The application server sends a small MQTT message instead of fetching megabytes of connector binaries from the database.
This is not a novel pattern. It echoes the command-query separation found in CQRS architectures, the worker-pool model common in job processing systems, and the general principle of separating concerns by computational profile.
What Changes
Several properties shift when adopting this pattern:
Resource isolation. Connector failures—whether from slow queries, memory exhaustion, or database timeouts—no longer destabilise the application server. The stream hosts absorb the impact. The application continues serving pages, perhaps with degraded data, but without cascading failure.
Independent scaling. The application server scales based on user concurrency and page rendering load. The stream host collection scales based on query volume and complexity. These are different scaling curves, and separating them allows more precise resource allocation.
Payload flexibility. In-process connectors face practical limits on payload size—the application server’s memory budget must accommodate page rendering and data transfer simultaneously. With distributed connectors, large payloads transit through a message broker designed for high-throughput data transfer. The application server receives results incrementally.
Latency characteristics. The distributed model adds network hops—requests travel through a message broker rather than executing locally. In theory, this overhead could matter for very lightweight connectors with minimal loading cost. In practice, the connector loading overhead in the in-process model dominates: our measurements showed the distributed model responding significantly faster for data retrieval, despite the additional network communication.
Measuring the Impact
We instrumented both approaches under identical conditions: same application server, same database, same page rendering workload. The test simulated realistic full page loads—multiple API calls per page, including authentication, metadata, and data retrieval.
Test Context: We deliberately used constrained infrastructure—below typical production sizing—to stress-test architectural limits. The improvement ratios are consistent across infrastructure sizes, but absolute capacity depends on your specific deployment.
The differences were substantial:
| Metric | Distributed Advantage |
|---|---|
| Concurrent users supported | ~5× more |
| Page loads completed | ~50× more |
| Median page load time | ~3× faster |
| Success rate | Higher reliability |

The in-process model reached its threshold at a certain concurrency level, at which point response times exceeded acceptable limits and the test automatically halted. The distributed model handled approximately 5× more concurrent users while maintaining responsive page loads.
Perhaps more telling: we later tested pages with multiple data sources. A page with three data grids, each querying the database independently, showed dramatic differences—the distributed model completed orders of magnitude more page loads under the same conditions.
The architectural change—not hardware upgrades—unlocked the capacity.
When to Consider This Pattern
The distributed connector pattern is not universally superior. It introduces operational complexity: a message broker to maintain, a stream host collection to monitor, and network communication to secure. For applications with modest concurrency and simple data requirements, in-process connectors remain appropriate.
Consider the distributed pattern when:
- Concurrent user growth is outpacing infrastructure scaling
- Pages are data-rich, requiring multiple data sources per view
- Payload sizes are growing beyond comfortable in-process handling
- Connector stability is affecting overall application reliability
- Scaling curves differ between page rendering and data retrieval workloads
The pattern offers a path to scale that doesn’t require proportionally larger application servers. In our measurements, the same infrastructure served ~5× more users. That efficiency gain compounds as deployments grow.
The Bigger Picture: Integration Consolidation
Beyond performance, adopting the distributed pattern reflects a broader architectural strategy: consolidating all integrations into Data Streams.
Historically, XMPro maintained two integration systems—connectors for application data access, and agents for stream processing. Each required separate development, testing, and optimisation effort. The in-process connector model—designed for simplicity—becomes a constraint at enterprise scale.
By routing application data requests through Data Streams, we unify these systems. The benefits compound:
- Single optimisation target — Engineering effort focuses on one integration runtime, not two
- Shared infrastructure — Stream hosts serve both real-time processing and application data needs
- Consistent patterns — The same agents that power streaming analytics also serve page data
- Simplified operations — One system to monitor, scale, and maintain
This isn’t just about making pages load faster. It’s about building a foundation where integration improvements benefit the entire platform—streaming and interactive workloads alike.
What’s Next
In the next post, we’ll examine the load testing methodology in detail—how we measured full page loads rather than individual endpoints, why that distinction matters, and what the response time distributions reveal about each architecture’s behaviour under pressure.
This is part 1 of a series on distributed architecture patterns. The series draws on load testing conducted on XMPro Application Designer, comparing in-process SQL connectors with distributed stream-based connectors. The distributed connector capability is planned for an upcoming 2026 release.